Data Scraping
Scraping with Python, Selenium and BeautifulSoup
Governments don’t always want to share their databases in response to Freedom of Information requests. But if the data is posted online, there’s a workaround. I’ve outlined here my experience scraping data from webpages using basic programming and Google Docs.
New incorporations
To master website scraping, I decided to initially focus on .aspx databases, including the Secretary of State’s new incorporations page. These are notoriously difficult to scrape because the url doesn’t change when search options change or the search button is pressed. In order to get the page to a place where there was scrapable information, I had to manipulate the Javascript on the page. To do that, I used Selenium, a Python module, to open the new incorporations page and click the search button. I then downloaded and parsed the html using BeautifulSoup, a Python module that parses data trees to find the table where information was stored. Finally, I parsed that table in Python and wrote it to a CSV file.
Food inspection database
Looking at Ryan Thornburg’s unsuccessful quest to get a copy of the database containing food establishment inspections maintained by North Carolina’s Department of Health and Human Services, I decided to give scraping their website a whirl based on what I learned from the Secretary of State’s website. This proved extremely complicated, but this is essentially how this scraper works:
Conveniently, every establishment has a unique number associated with it that is referenced in its url. These unique numbers go from 1 to 152,468 as of March 4. You can look at an establishment’s basic information — but not its food inspection scores — using this URL.
Base url: https://public.cdpehs.com/NCENVPBL/INSPECTION/ShowESTABLISHMENTPage.aspx?
Appended establishment id: ESTABLISHMENT=147174
I used Selenium to open Firefox windows for each establishment and scraped the name, address, phone and county. In order to get the food inspection information, I had to append an additional county code to each url.
Base url + establishment id: https://public.cdpehs.com/NCENVPBL/INSPECTION/ShowESTABLISHMENTPage.aspx?ESTABLISHMENT=147174
Appended county code: &esttst_cty=68
In order to get the page to a place where it can be scraped, the program does the following:
- Opens Firefox
- Iterates the establishment id by 1
- Gets the county from scraping the page without inspection information
- Closes Firefox
- Finds the county code associated with the county name
- Opens Firefox
- Appends the county id to the url
- Gets the food inspection information
- Closes Firefox
And here’s an example of it’s output:
Scraping with Python and CSV tools
Euthanasia in North Carolina Animal Shelters
Last year, I worked on a project for The News & Observer that sought to find out how many animals were euthanized in the state. I wrote a program in Java to read through a CSV file and reorganize it so the data was usable. The program seemed overly complicated.
This year, I decided to look at the same set of data for 2012, which is a newly released. I initially sought to use ScraperWiki to accomplish this task, but decided against it because there were no libraries built in to convert from .xls to .csv. I downloaded the Excel file to my computer, converted it to a CSV and wrote this program in Python to find the euthanasia rate for cats and dogs in North Carolina. This took far less time than using Java.
Here’s the before and after (see the tabs on the bottom):
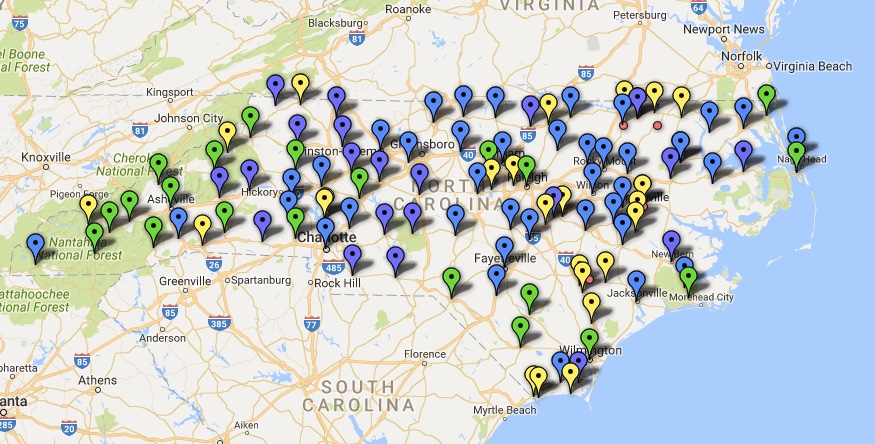
I geocoded the shelters to the city they were located in and created this map in Fusion Tables with color-coded pins.
Scraping with Google Docs
Triangle Adult Care Center Penalties
I found this site, which displays penalties associated with adult care centers in the state. I scraped the violations for Wake, Durham and Orange Counties using Google Doc’s importHTML function (see the tabs on the bottom).
Related posts
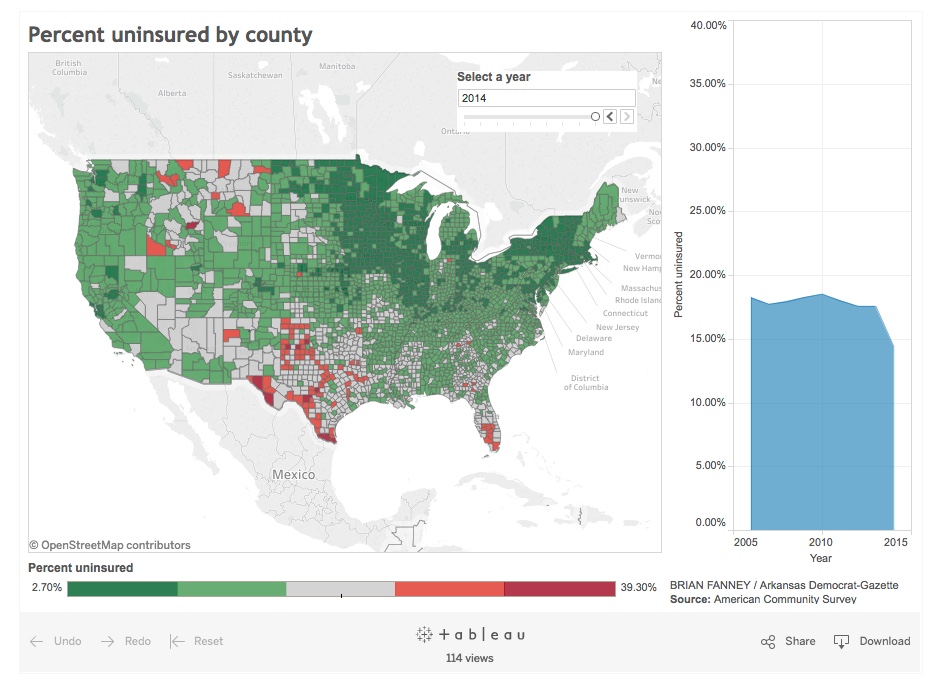
Data visualization
As a data-centric reporter, I map data in order to understand it. Below are several examples. Click on the images…